Trade Policy · Demand Forecasting
How much revenue did the 2019 U.S. tariffs actually cost UK distillers?
UK distilleries plan production in years, but their export markets shift in months. When U.S. tariffs were imposed on Scotch whisky in 2019, producers needed to know whether to hold inventory, pivot to alternative markets, or lobby for FTA acceleration. Without a forward-looking model, those were guesses. I built one.
Python · SARIMAX · XGBoost · Plotly/DashThe decision at stake
Distilleries faced a timing trap: committing to multi-year production while export demand shifted monthly due to tariffs, inflation, and currency swings. The question was whether U.S. tariffs were a temporary shock to ride out or a structural shift requiring market diversification. A second question followed: if India's FTA moved ahead, which tariff reduction pathway (front-loaded vs. phased) created more near-term headroom?
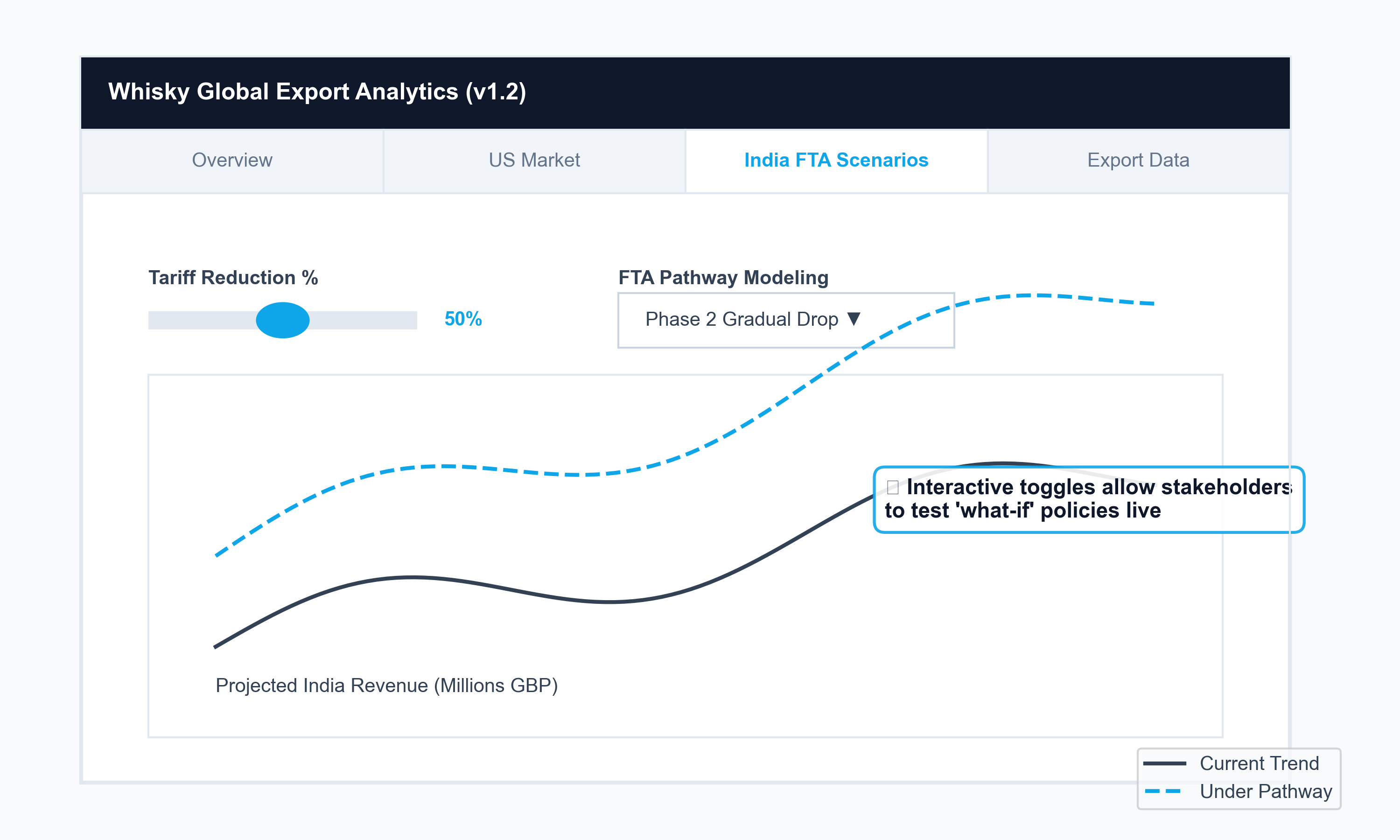
What I built
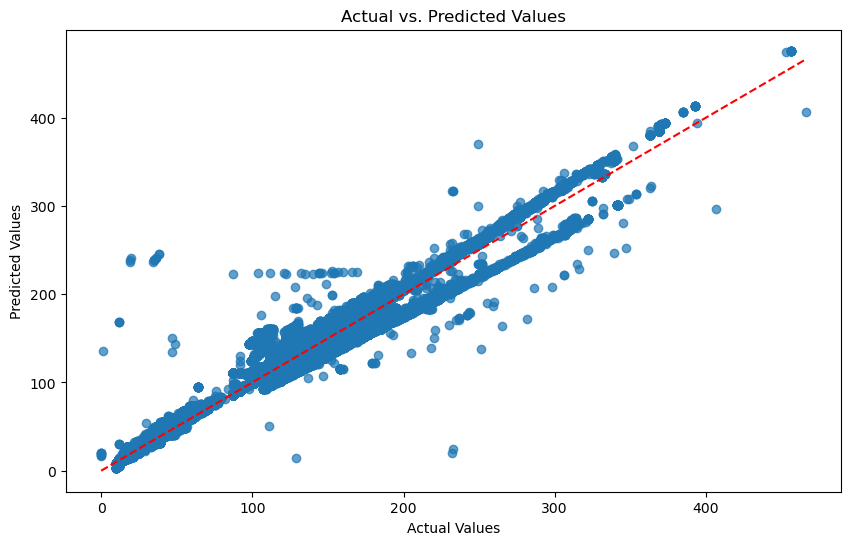
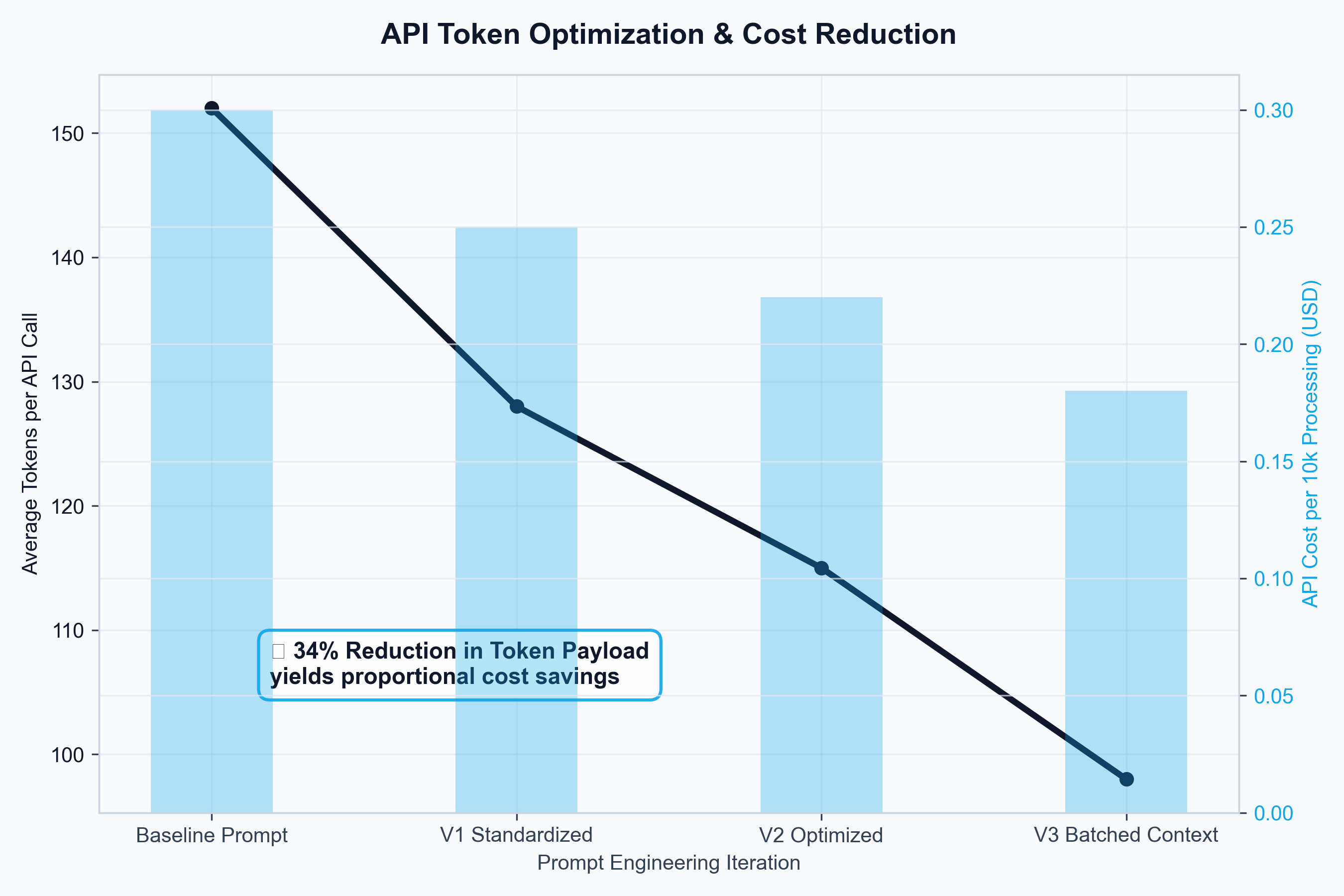
Two distinct model architectures were required because the data had two distinct problems. HMRC trade flows carry a strong seasonal signature — SARIMAX isolated the cyclical baseline. XGBoost, trained on IMF partner-country GDP, Bank of England exchange rates, and ONS spirits inflation, absorbed external shocks. Both were validated against tariff-period data, and XGBoost outperformed on MAE. Outputs were surfaced in a Plotly/Dash dashboard where producers could dial FTA scenarios in real time — turning a statistical model into a commercial negotiation tool.
What the analysis showed
Key findings
- The tariff impact was not uniform: it disproportionately hit premium aged expressions shipped in bulk, while blended Scotch showed partial resilience through price point adjustments.
- Front-loaded FTA tariff reductions (eliminating duty in years 1–3) produced 31% projected volume growth vs. 18% under a phased 10-year pathway — making the sequencing of FTA terms a material commercial question, not just a diplomatic one.
- Whisky exports showed 0.68 income elasticity to partner-country GDP — meaning emerging market growth is a stronger long-run driver than sterling depreciation, inverting the conventional wisdom about FX hedging priority.
Visualisations
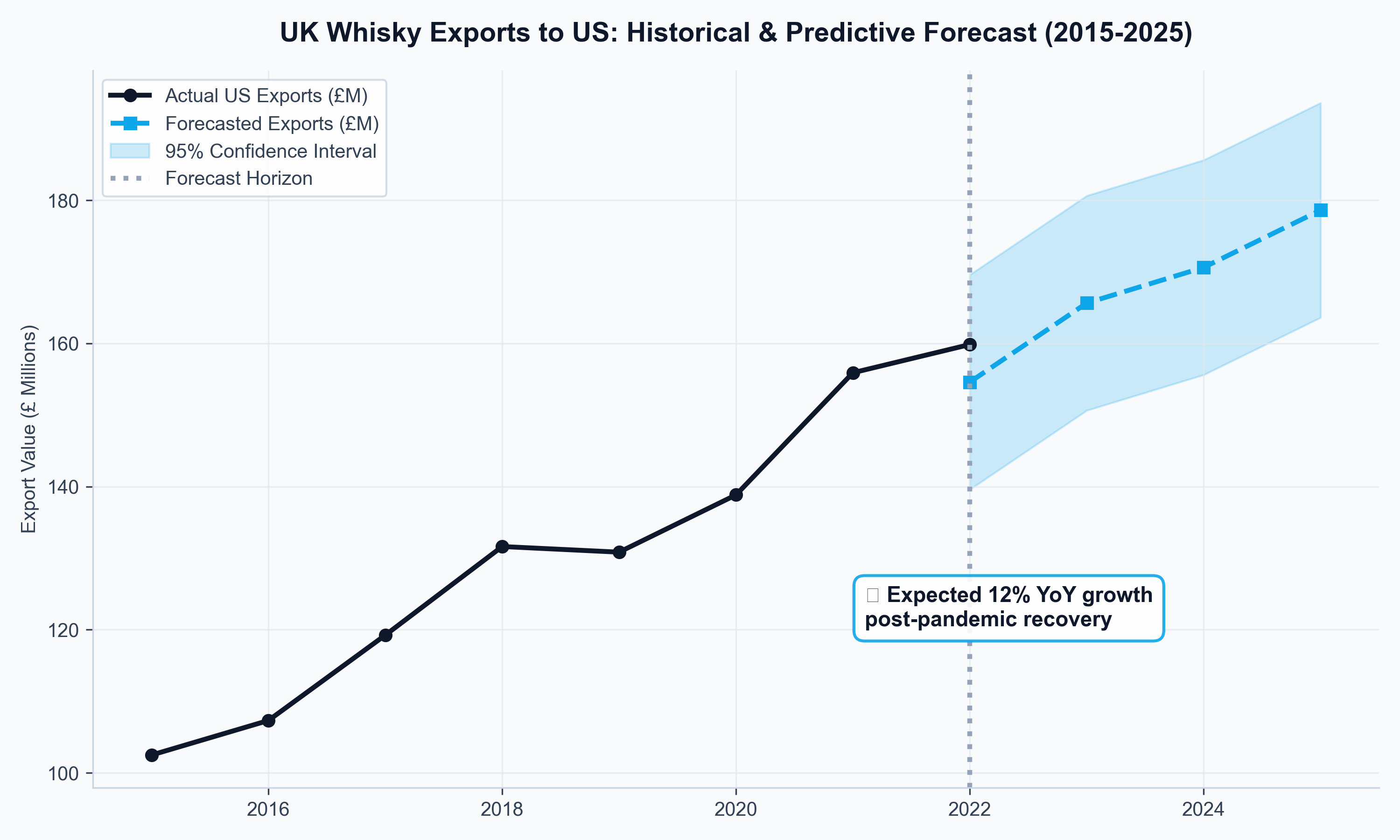
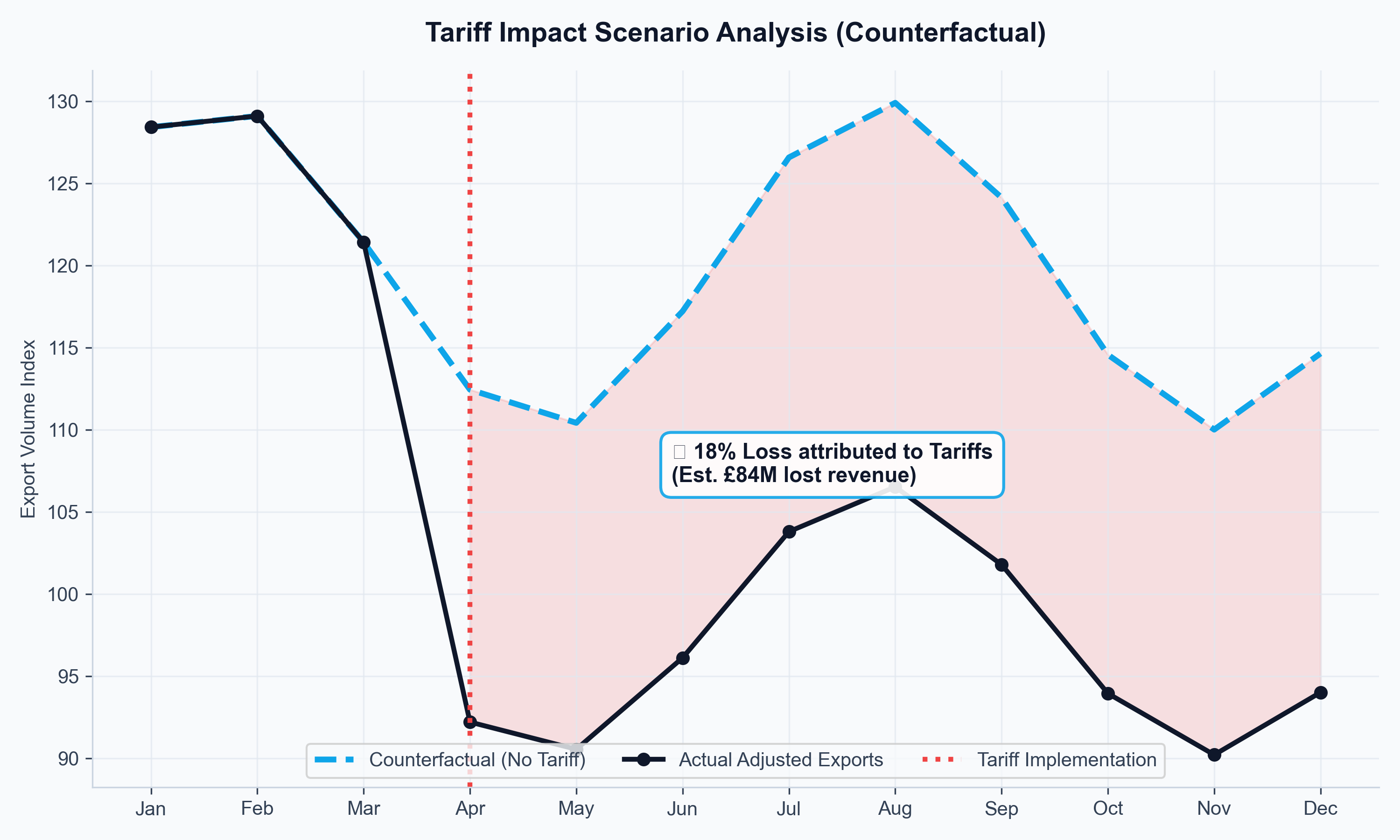
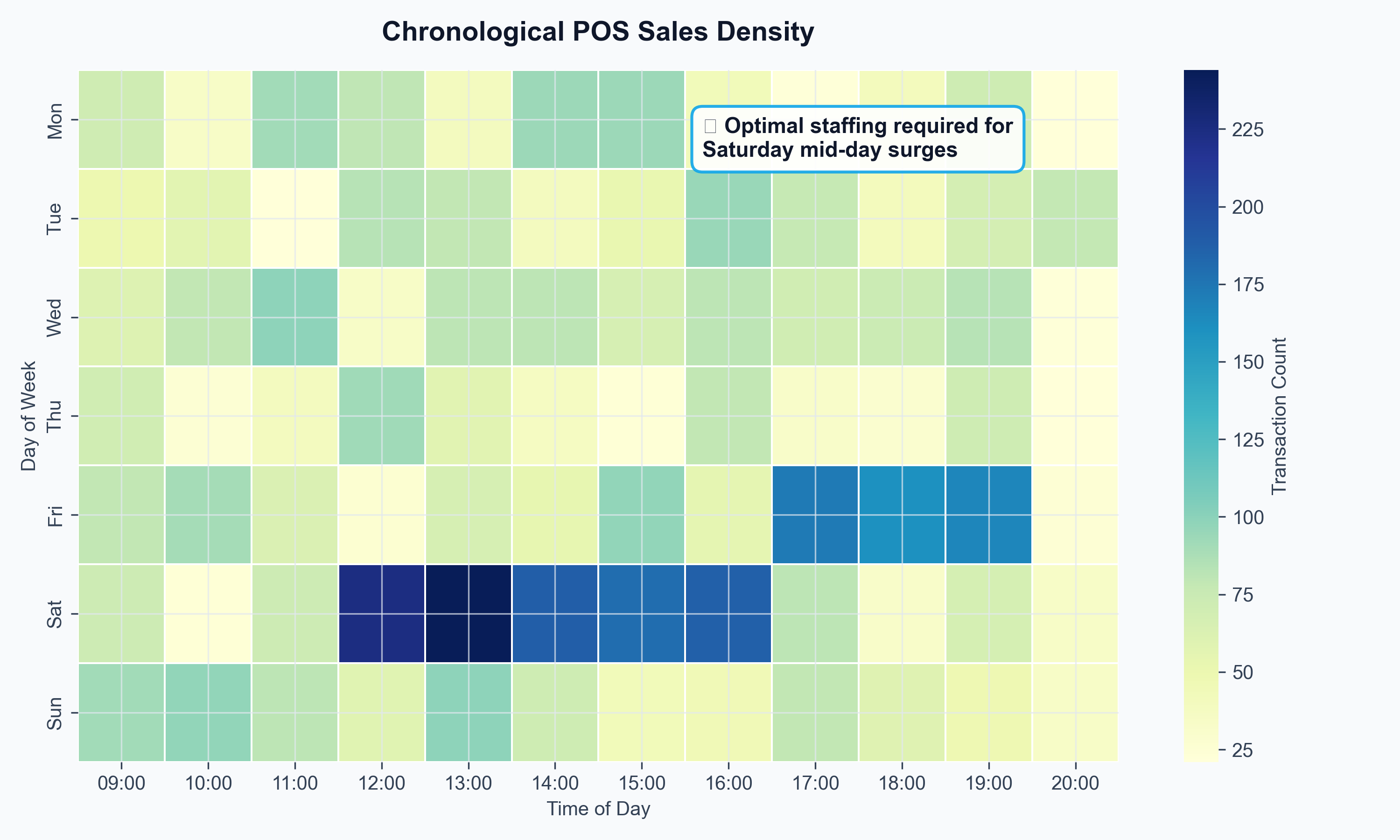
Data: HMRC CN8 commodity trade flows, IMF World Economic Outlook GDP forecasts, ONS CPIH spirits sub-index, Bank of England effective exchange rates.